Avril 2022. Atlassian met hors ligne, accidentellement, 775 entreprises clientes. Leur Jira, leur Confluence, leurs projets, leurs données — inaccessibles. Pendant 13 jours.
Sur le relevé mensuel, le chiffre d'uptime affiché était de 73 %. Le SLA contractuel : 99,9 %. L'indemnisation maximale prévue au contrat : 50 % d'une mensualité. Pour une entreprise à 10 000 $/mois, cela représentait 5 000 $ de crédit. Pour les mêmes entreprises, le coût réel de deux semaines de paralysie — projets bloqués, équipes à l'arrêt, confiance détruite — se chiffrait en dizaines, voire en centaines de milliers de dollars.
Ce n'est pas une histoire d'incompétence. C'est une démonstration que le chiffre affiché et la réalité vécue peuvent diverger complètement. Et que la façon dont l'uptime est calculé détermine ce qu'il représente vraiment.
Un chiffre, des réalités très différentes
99,9 %. C'est ce que la plupart des outils affichent. C'est ce que la plupart des SaaS promettent dans leur contrat. C'est aussi un chiffre qui peut signifier des choses très différentes selon la méthode de calcul utilisée.
Traduit en temps réel, le tableau est éclairant :
| SLA | Interruption annuelle | Interruption mensuelle |
|---|---|---|
| 99 % | 3 jours 15h | 7h 18min |
| 99,9 % | 8h 45min | 43min 50s |
| 99,99 % | 52min 35s | 4min 23s |
| 99,999 % | 5min 15s | 26s |
La différence entre "trois neuf" et "quatre neuf" n'est pas marginale : c'est la différence entre une interruption potentielle de 8 heures par an et une de moins d'une heure. Pour un outil de productivité, une API critique, un service de paiement, cet écart représente quelque chose de concret — pour vos équipes, et pour vos propres clients.
Mais ces chiffres n'ont de valeur que si le calcul qui les produit est honnête. Et c'est là que les choses se compliquent.
Comment Perimon calcule votre uptime
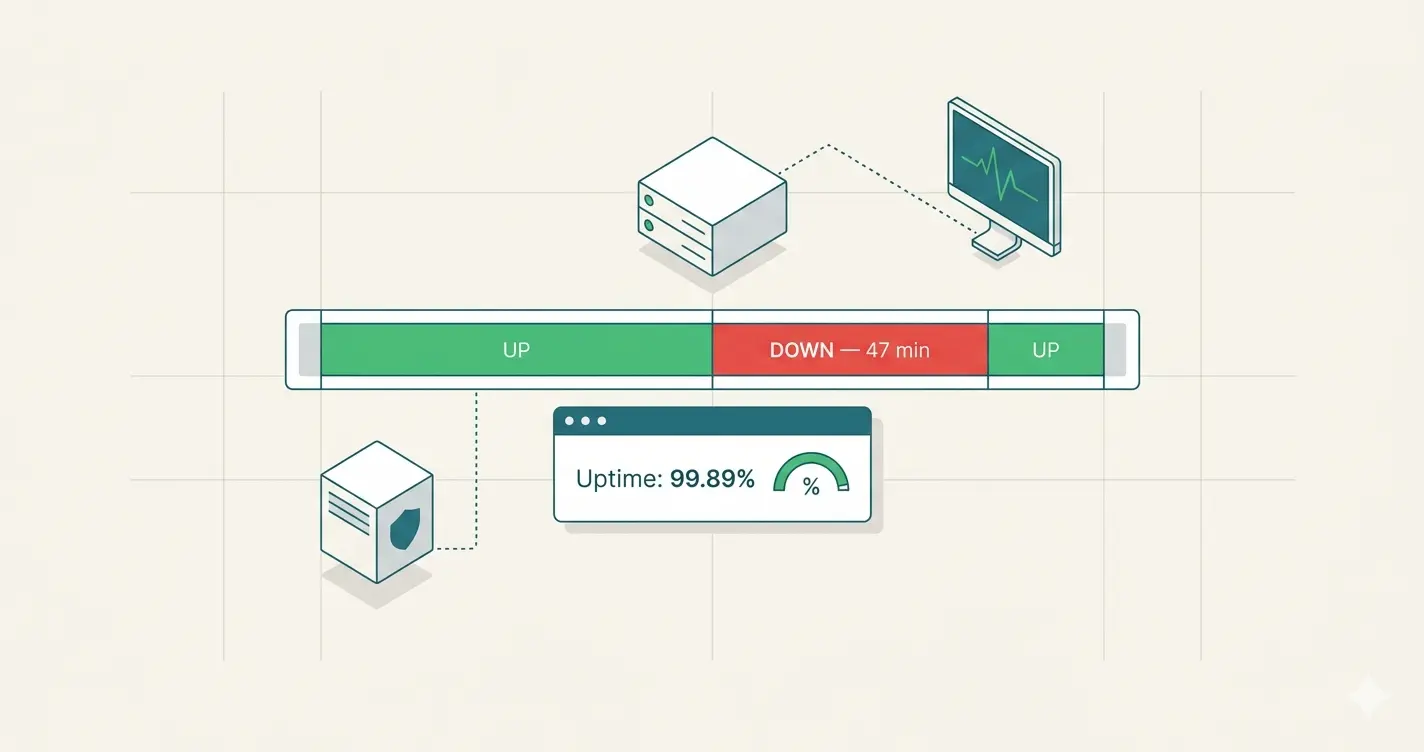
Perimon ne compte pas les checks échoués. Il mesure des périodes d'interruption — du moment où un incident est déclaré jusqu'au moment où il se résout. La différence entre les deux approches n'est pas anecdotique : c'est ce qui détermine si le chiffre affiché représente quelque chose de réel.
Du check à l'événement : le pipeline
Quand le seuil est franchi, Perimon émet un événement horodaté :
L'événement FIRED marque le début de l'interruption avec un timestamp précis. L'événement RESOLVED en marque la fin. La paire constitue une période d'incident mesurable à la seconde.
Détection avec hysteresis
Pour qu'une erreur ponctuelle — timeout réseau ponctuel, pic de charge passager — ne déclenche pas de fausse alerte, Perimon analyse les 3 derniers checks consécutifs avant de déclarer un incident :
- Entrée en incident : ≥ 2 checks en erreur sur les 3 derniers
- Sortie d'incident : ≤ 1 check en erreur sur les 3 derniers
Ce seuil asymétrique — plus strict pour entrer que pour sortir — s'appelle l'hysteresis. Il absorbe les erreurs éphémères sans masquer les vraies pannes, et évite le flapping : un service instable qui oscille entre erreur et succès ne génère pas une succession d'alertes contradictoires.
La contrepartie de cette fenêtre de 3 checks, c'est la latence de détection : si les checks s'exécutent toutes les 5 minutes, un incident peut mettre jusqu'à 10 minutes avant d'être officiellement déclaré. Pour compenser, Perimon utilise un fast recheck : dès qu'un check revient en erreur sans que le seuil soit encore franchi, un nouveau check est déclenché après un court délai — sans attendre l'intervalle planifié suivant. Même logique à la sortie : si un incident est actif et qu'un check revient positif, Perimon recheck rapidement pour confirmer le retour à la normale avant d'émettre l'événement RESOLVED. Le fast recheck réduit le MTTD à l'entrée, et le MTTR à la sortie — sans sacrifier la robustesse anti-flapping.
La formule
uptime % = (durée_totale − downtime_cumulé) / durée_totale × 100
Sur 30 jours : si les incidents représentent 47 minutes d'interruption cumulée, l'uptime est de (43 200 min − 47 min) / 43 200 min × 100 = 99,89 %. Pas une estimation à partir d'échantillons. Une mesure à partir de périodes réelles.
Le problème du double-comptage
Mesurer des périodes soulève un défi concret : que se passe-t-il si deux incidents se chevauchent ?
Cas concret — deux incidents simultanés sur la même fenêtre (HTTP 503 + SSL expiré) :
Additionner les deux incidents reviendrait à compter deux fois la fenêtre 10h15–10h25. Perimon applique un algorithme de fusion d'intervalles : les périodes qui se chevauchent sont fusionnées avant le calcul. Le downtime cumulé représente toujours le temps réel pendant lequel le service était indisponible pour vos utilisateurs — sans redondance.
Ce même mécanisme gère les cas limites naturellement :
- Un incident démarré avant la période analysée est tronqué à
début_période - Un incident encore actif à la fin de la période est tronqué à
fin_de_la_période - Une période sans aucun incident retourne 100 %
Pour Perimon, l'absence de preuve d'interruption est traitée comme une disponibilité complète
Ce que votre uptime ne vous dit pas seul
Le livre SRE de Google formule quelque chose de contre-intuitif : "A user on a 99% reliable smartphone cannot tell the difference between 99.99% and 99.999% service reliability." Au-delà d'un certain seuil, le gain marginal de fiabilité coûte exponentiellement plus cher — et reste imperceptible pour l'utilisateur final.
Ce n'est pas un argument pour se contenter du minimum. C'est un rappel que le chiffre d'uptime, aussi honnête soit-il, ne répond pas seul aux deux questions qui comptent vraiment au moment où quelque chose ne va pas :
Est-ce que vous l'avez su à temps ? Chaque minute d'incident non détecté, c'est des utilisateurs qui abandonnent, des transactions qui échouent, des tickets support qui s'accumulent. Le chiffre d'uptime enregistre la panne après coup. Une alerte immédiate, c'est la différence entre une interruption de 3 minutes et une de 45.
Est-ce que vos utilisateurs le savent ? Quand un service est dégradé, les utilisateurs ne savent pas si le problème vient de leur connexion, de leur configuration ou de vous. Ils relancent leur navigateur. Ils ouvrent un ticket support. Ils perdent confiance. Ce doute a un coût — en temps, en frustration, en relation client.
Comment Perimon répond à ces deux questions
Perimon calcule l'uptime à partir de périodes d'interruption réelles. Mais calculer juste ne suffit pas.
Sur le temps de réaction : dès qu'un incident est déclaré une alerte part immédiatement. L'objectif n'est pas de constater la panne dans le dashboard le lendemain matin. C'est d'être notifié au moment où le seuil bascule, pour agir avant que l'interruption de quelques minutes ne devienne une heure de downtime dans les logs de fin de mois.
Sur la confiance utilisateur : chaque incident détecté par Perimon peut être reflété en temps réel sur une page de statut publique. Vos utilisateurs voient l'état de vos services, la timeline des incidents en cours et résolus, sans avoir à contacter votre support pour savoir si "c'est chez eux ou chez vous". Pendant une panne, la transparence ne compense pas l'interruption — mais elle évite le doute, réduit la charge support inutile, et préserve la relation.
Un uptime honnête mesure ce qui s'est passé. Les alertes réduisent le temps que ça dure. La page de statut gère ce que vos utilisateurs vivent pendant que vous intervenez. Ce sont trois réponses à trois problèmes distincts — et les trois comptent.